

About Client
Masterworks
Based near Seattle, Masterworks helps move the hearts and minds of people to act for Christian ministries across America. For more than 30 years, the company has partnered with an exclusive group of ministries to build passionate audiences and raise money for their missions by providing solutions that help engage with constituents through creative marketing campaigns and best-of-breed technologies.
Identify Machine-Learning Expert to Migrate Application in 8 Weeks
A key service Masterworks provides to its clients is an application that uses machine-learning models to measure the propensity that an organization’s members will donate to a particular fundraising campaign. Clients use intelligence produced by the audience selection tool to narrow down their member databases and focus marketing efforts on segments most likely to give money and other gifts. The service essentially allows clients to reduce the expenses of fundraising campaigns while increasing net revenues.
“We relied on a hosted SaaS application that was working well enough, but the provider’s licensing model made it difficult to operate the application profitably as we expanded our client base,” says Milo McDowell, Senior Vice President of Operations for Masterworks. “As our hosting contract began to approach the annual renewal date, we decided to look for a lower-cost hosting provider.”
To reduce the costs for hosting the machine-learning application, McDowell first turned to Amazon Web Services (AWS), the cloud platform Masterworks has relied on for many application workloads for more than 10 years.
McDowell realized AWS could offer a cost model that would reduce the expense of hosting the application and that Amazon SageMaker provides a platform to streamline processes to create, train, and deploy machine-learning models in the cloud. McDowell also realized he would need help in migrating the application to AWS. “We did not have the capacity on our internal staff to handle such a complex project,” McDowell explains. “We also did not have anyone on our team with relevant SageMaker experience.” Thus, finding a SageMaker expert became the prime need. But Masterworks also faced another challenge. “We had about eight weeks to complete the migration before our hosting provider contract would renew,” McDowell shares. “So we needed to make sure we could complete the project relatively quickly.”
Avahi Instills Confidence to Migrate 200 Models On Time
Thanks to a strong working relationship with AWS, an answer for McDowell was right around the corner as AWS referred Masterworks to Avahi. After the initial meeting to discuss migrating the machine learning models to SageMaker, McDowell felt confident Avahi could complete the project within the short timeline.
“The Avahi team dived right in to assess the 200 models used by 35 clients that we needed to replicate,” McDowell says. “They demonstrated their experience with SageMaker and took the time to understand our needs. From there, Avahi developed a plan for how to complete the migration by our deadline while also recommending ways to enhance our machine-learning models.”
Given the pending deadline and the confidence Avahi instilled, McDowell did not consider collaborating with any other firms. “From the developer to the project manager and the CEO, Avahi impressed us with their commitment to delivering the project on time,” McDowell says. “We did not feel like we were taking a risk with Avahi.”
Solution Design Results in Zero Post-Production Issues
Avahi created a pre-processing workflow using the Matillion ETL tool to extract and store data as a .csv file in Amazon Simple Storage Service (S3). The workflow also transforms the data model into fixed features as expected by SageMaker to predict target variables and generate results.
As illustrated in the diagram below, SageMaker reads the input files and infers predictions using hosted models to generate results:
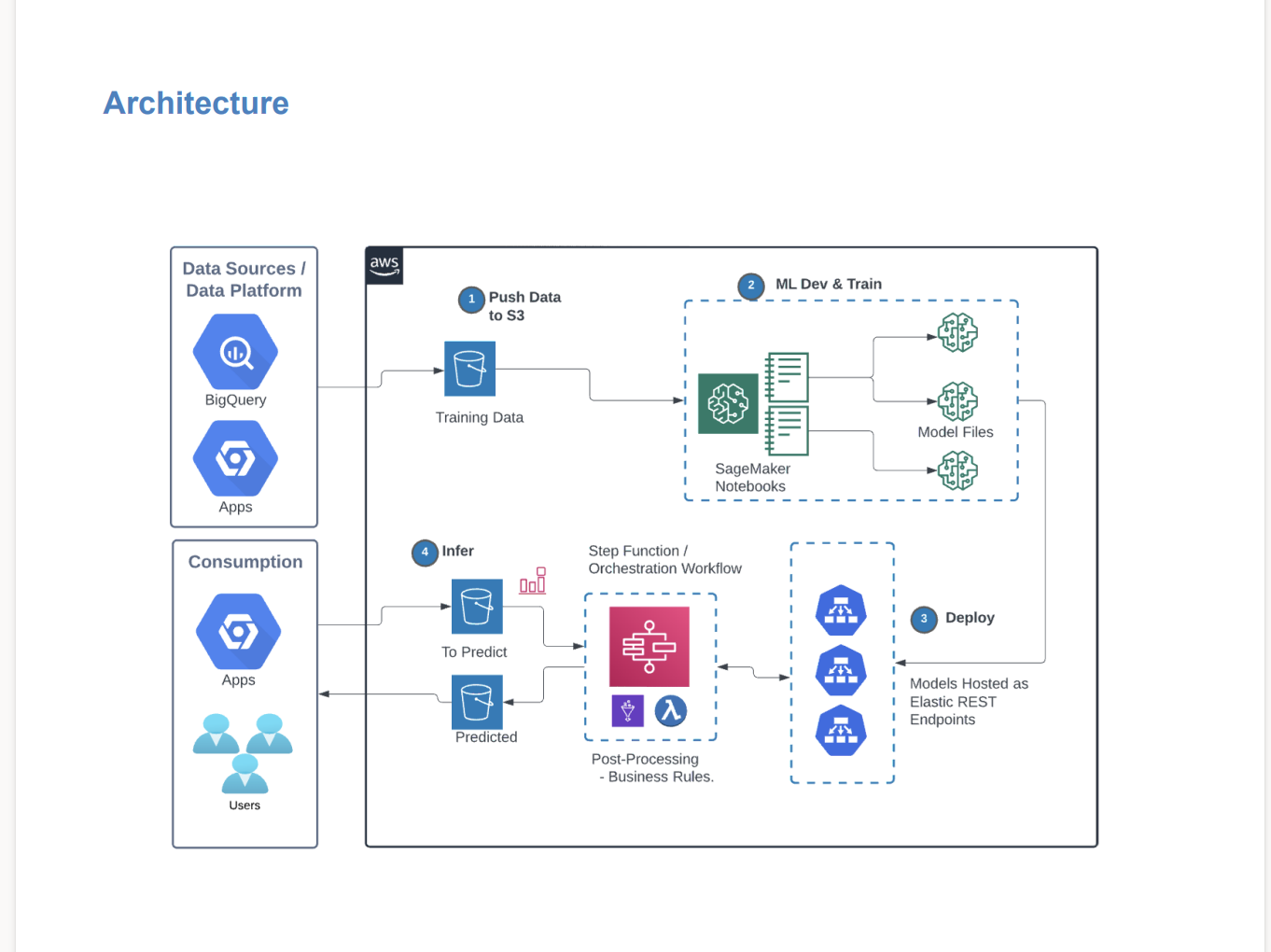
SageMaker also provides batch transformation jobs via an API that does not require a dedicated hosted endpoint for a model. With this capability, Masterworks can run comparisons between two batches of inference results.
The model training pipeline has six model versions for each Masterworks client that can be used for different types of predicted targets, and the system automatically trains, tunes, and selects the best model for each type of inference to make it readily available on-demand. Masterworks can easily leverage the input to train models for a new client or retrain newer versions for existing clients.
The inference pipeline is cost-optimized by relying on serverless computing (powered by AWS Lambda and AWS Glue) and on-demand batch requests. The pipeline also automatically generates predicted results when a file is dropped into S3. In addition, the pipeline chooses the latest version of the model for a client and model type if there are multiple versions of the same type of model.
“The project went smoothly, and it was clear the Avahi team worked hard to make it happen,” says McDowell. “As we cut over and went live into production, we needed to adjust how the models run inferences. Avahi quickly helped us determine how to reprocess jobs—their team worked well with our team, and we haven’t had any issues since going into production.”
Costs Reduced 75% as Model Processes Accelerate
By migrating the machine-learning model application to AWS, McDowell estimates Masterworks has reduced hosting and usage costs by approximately 75 percent. One of the reasons why AWS is less costly than the previous provider is that Masterworks can use compute resources on-demand. With the previous SaaS platform, Masterworks was assigned dedicated machines that were always running.
“We also save because the AWS licensing model is different,” adds McDowell. “We pay for compute resources in AWS, but we don’t have any user charges to go along with that. The SaaS provider charged a licensing fee for each user, and where our utilization rate falls between 5-10 percent, it was not a good use of our money to spend it on a full-time state-of-the-art machine learning platform.”
In contrast, migrating to the AWS platform allows Masterworks to run the same data models without paying the hefty overhead of the previous platform. “And as we use additional resources to develop new models with SageMaker, there’s no overwhelming pressure that we’re spending too much money on licenses,” McDowell points out. “We’re spending dramatically less and can maximize our machine learning efforts.”
The money Masterworks is no longer spending on the previous machine learning platform can now be invested in other initiatives. And in addition to the cost savings, McDowell says the processes to train new models and run inferences run faster in the AWS environment faster. “By running new data against a trained model to infer what will happen during fundraising efforts, our engineers can generate more accurate results for clients to measure the propensity that members will donate to various campaigns,” says McDowell.
This capability helps clients evaluate campaign strategies before investing resources. And life is also better for the Masterworks engineers working in SageMaker. They can run model training and inferences concurrently, and they benefit from the detailed solution documentation provided by Avahi. “Our engineers refer to the documentation if they have questions relating to the resources, and we can more easily cross-train other engineers on our internal team,” McDowell says. “We now have a structure for building training new models with a detailed process that our engineers are comfortable with.”
Partnership Offers Powerful Combination of Skills
Streamlining the process to build and train data models is vital as Masterworks goes through model training each time a new client comes on board. “We’re also always working to improve our services, so as we innovate, we go through rigorous testing of new ideas and can incorporate them into the models for existing clients,” McDowell says.
In addition to the data modeling project, Avahi is upgrading the code base of an Epiphany application so it will work properly in the modern AWS compute environment. “We work with a lot of consultants and partners, and Avahi stands out for their machinelearning expertise as well as the effort they put in and the documentation they provide,” says McDowell. “That’s a powerful combination of skills, and it’s rare to see an IT partner deliver on all three the way Avahi does.”
Key Challenges
- Reduce SaaS machine-learning platform costs.
- Avoid diverting the internal IT team from core responsibilities.
- Identify expertise to migrate to a new machine-learning platform in eight weeks.
Key Results
- Avoided SaaS renewal fees by completing migration on time.
- Decreased application hosting and license costs by 75%.
- Accelerated model training and inferences processes.
- Provided detailed documentation to assist internal engineers with data model resources.
AWS Services
- Amazon SageMaker
- Amazon Simple Storage Services (S3)
- AWS Lambda
- AWS Glue
Third-Party Tools & Integrations
- Matillion ETL
